Over the past few years, we have seen data security moving away from the database layer into the application/business logic layer. In a two-tiered environment, the presentation layer used the authentication and authorization mechanism of the database management system (DBMS). But now, in most architectures, data protection is not a database layer’s job; rather, it is the job of one of the application layers. Although the industry is moving in this direction, I believe, security-wise, this is the wrong way to go. This trend creates a weak link in the application security architecture. In this article, I will explain the reasons for this architectural trend, the security issues related to this architecture, and then will touch upon best practices that can be applied for this architecture.
In this era of connected computers, data drives everything. Web sites and multitier applications store their data in relational databases. The first time we browse to a Web site, data collection starts. Some Web sites log every user action and use this information to tailor response to user needs. Our driving records, medical records, educational records and credit history are all data. Business decisions are made using data, and our bank accounts are nothing but data residing in a central bank computer. All this data is kept in databases, mostly relational database management systems (RDBMSes). For all businesses, these databases are actually a great responsibility. Businesses are responsible for keeping the data that they capture intact and confidential. They need to log all the accesses to collected data. Some legislation, such as HIPAA (Health Insurance Portability and Accountability Act) and CISP (Cardholder Information Security Program), regulate data privacy and require data access logging to protect data and consumer privacy.
One would think that, in today’s security-conscious era, we would be implementing a more active logging mechanism to guard data access. However, the industry is moving in a direction where accountability of data access is given to a layer that is far away from where data actually resides. Current industry trends move data integrity and confidentiality responsibilities away from DBMSes and give these responsibilities to an upper layer, either a business or an application layer. Since this upper layer is away from the data, it cannot truly provide complete and accurate data access and manipulation information. Proof of nonrepudiation of data changes cannot be accurately obtained. A real end-to-end digital signature can easily be compromised. Information about who accessed what data and when, and who did what to which data is not truly available. This information is derived or obtained from a layer that is actually far away from the data.
Day by day, we are moving toward technologies that tend to take data security in their own hands, and by doing so these technologies compromise data integrity and confidentiality.
Data Security Types
For simplicity’s sake, we divide data security into two types: database layer data security, in which the DBMS deals with authentication, authorization and access logging of users by means of features such systems provide; and non-database layer data security, an upper-level form of security in which a non-DBMS authorization and authentication mechanism is used and the DBMS is used with generic user accounts. Non-database layer security includes such things as object-level security and directory-level security. We will analyze them to see how each works and what capability each provides.
Database layer data security: Traditionally, relational database management systems have implemented sophisticated security mechanisms to protect data. Data stored in a DBMS is not directly visible to the user. All data access is requested through the management systems of the DBMS. Most of the time, this level of protection is good enough so that every business trusts RDBMSes with the task of storing its most valuable asset: data. In the past few years, commercial RDBMS vendors have added more sophisticated security mechanisms, including row-level authorization, before-and-after triggers and instead-of triggers. In a database system, authentication is just the first part of the security because the DBMS allows storage of all kinds of data for all types of users.
Here is a summary of the security services that popular DBMSes provide:
- Content-dependent access control. Some users can access some data but not all data. Some users can access some data only within a particular time frame.
- Role-based and rule-based access to data.
- Cell suspension, partitioning, and noise and perturbation techniques to prevent unauthorized data access.
- View-based security for data.
- Control mechanisms for data view and data manipulation.
- Trigger functionality. Triggers are independent pieces of code that are executed whenever data is inserted, updated or deleted. This mechanism provides a greater level of security. For example, users who are authorized to adjust loan records can go into the database and remove their own loan records. In this case, triggers can check user names at record deletion time to make sure users are not deleting their own loan records. Triggers also provide ways to selectively restrict user access based on the time of day. This feature provides content-dependent, time-sensitive, user-based access control. Triggers also provide easy and accurate logging mechanisms. If a DBMS knows who is actually manipulating data, then it can implicitly log as data is modified.
- Data access encapsulation within stored procedures to provide an accountable and robust security mechanism. Data exposed only through stored procedures allows easy logging of data access at the source level. Stored procedures can also be used as object method data providers, when using an object-oriented approach.
- Row-level authorization. This feature allows security to be configured based on rows of data and individual data records.
In most secure RDBMSes, a user cannot open a DBMS file in a file system utility and access a piece of data. A user has to have a valid user name and password to be identified, authenticated and authorized before a piece of data is given out. DBMSes provide functionality to log and restrict all types of data access and manipulation. Since the DBMS is the lowest-level layer where data can be retrieved, it actually is the only place where proper data accountability measures can be placed to maintain data integrity and confidentiality.
The important thing to keep in mind is that a DBMS can know who is doing what only when users employ their own credentials to access data from the DBMS.
Non-database layer data security: With multitier architectures, security is moved into the application layer, which provides almost all of the security features I’ve mentioned, but is implemented in a layer above the data layer. The intelligence and data security provided by DBMS vendors is not used or is only partially used. The application layer mostly builds security based on objects. In well-designed multitier applications, objects are mapped to roles and users are given access to objects. The application layer usually has some type of authentication/authorization mechanism in place. In this security framework, the application layer calls some type of business layer object that in turn calls functionality-specific data access objects. These functionality-specific data access objects then retrieve data using a preinstantiated generic connection to the DBMS. These objects may ask the DBMS to provide some services. These preinstantiated generic connections usually are instantiated or connected to the database using DBMS security with a generic user name and password. This generic user is usually given complete access to data so it can serve all types of data requests. Since applications have a constant need to access data, there is usually more than one preinstantiated connection opened with the DBMS using this same generic user.
Some implementations take the extra step of having multiple generic users, each possessing limited, role-based access. However it is implemented, with some kind of connection pooling, multiple users access data with one or multiple generic user credentials.
The database blindly provides requested data, not knowing who actually requested the data and who actually will look at it. The identity of the user is not passed to the database, and the database assumes that a big, hungry user is accessing data again (the “big, hungry user” is the generic user whose ID is used to create preinstantiated database connections).
Data access logs with this type of framework cannot truly be considered complete or accurate in this architecture. Data access logs are the responsibility of the application layer and can provide only the data access story that the application server knows about. (The industry has recently produced a nice Java-based logging utility for the application level, Log4J (logging.apache.org/log4j/docs), but no work has been done on a database-level logging mechanism).
With this type of security, if someone uses the same account used by preinstantiated connections and directly accesses the DBMS, not through the application layer, there is absolutely no way to know who saw what data and how that data was compromised.
Sometimes the application layer voluntarily lets the DBMS know the user name for data that is accessed. However, this does not qualify for our definition of DBMS layer security. As long as the application layer is actually authenticating users, and then utilizing preinstantiated connections with generic users to access data, then it is non-database layer security.
An Example
To clarify the difference between these two types of security frameworks and indicate vulnerabilities, I’ll give an example. Let’s assume that data in the database is real money and the DBMS is like a bank. When a user is accessing data using database layer data security, the user is actually providing the bank with his or her credentials and the bank is personally verifying the credentials of the money (data) requester. All transactions are logged, and the bank knows who accessed which data and when.
On the other hand, in non-database layer data security, “Nobleman,” that is to say, a generic user logged into the DBMS utilizing a preinstantiated connection, is authorized to get into the bank and deal with everyone’s money (see Figure 1 (not yet available)). Here some “policeman” (that is, application level authentication and authorization) checks user credentials and asks Nobleman to pick up money from the bank for the user. While acquiring money for the user, Nobleman may or may not tell the bank whose account to credit and which account to credit.
Even if Nobleman decides to tell the bank whose account to credit, the bank does not know if Nobleman will actually hand over the money to the account holder. Nobleman just picks up the money from the vault and gives it away to the user. It is left up to Nobleman to decide what he would report to the bank. Reporting is totally discretionary to Nobleman. The bank has no say and no detailed knowledge of what amount of money Nobleman has given to whom. The bank (DBMS), however, knows at what time Nobleman took how much money. Now, even if we assume that Nobleman logs everything very diligently, we really don’t know if he has made a mistake or if someone else came to the bank disguised as Nobleman.
Let’s ponder this point a little. If someone else comes in Nobleman’s disguise, then the bank has no way of knowing if the money Nobleman took was actually given to a user and not to a malicious hacker. In this article I am arguing that Nobleman is very easy to disguise and a lot of people can get to his authentication mechanism.
The point is, logs created by Nobleman are incomplete and no one can assume that money (data access) disbursement logs are a complete account of actual money taken from bank. If we follow this example, we can add that application-level data access logging is equivalent to Nobleman’s produced log. We cannot accept Nobleman’s log as a complete and accurate log, since there can be somebody else who may have gotten the money from the bank.
In Figure 1 (below), a client/browser accesses the application-presentation layer to do some work. The presentation layer calls business objects or data access objects. Data access objects access data using connection pooling. The connection pool has a set number of connections already initiated with the database with a generic user credential who is authorized to do almost anything with data.
FIGURE 1: DATA ACCESS IN A MULTITIER ARCHITECTURE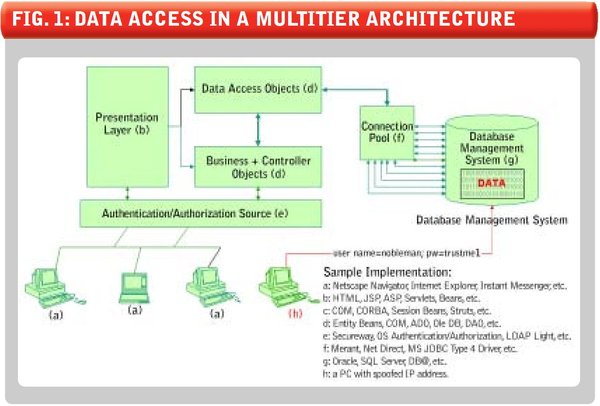
In this figure, we see possible access from a different user directly accessing the database with the same generic user credential, making it impossible for the DBMS to distinguish between the connection pool and this user.
Reasons for Non-Database Layer Security Trends
I want to review why the industry is moving toward non-database layer security. Here are the key points:
- The database is kept behind multiple layers of firewall and applications so that users do not have direct access to the DBMS. This mentality mostly comes from the fact that most security professionals are concerned about network security, and they think of security in terms of layers. The top layer is always kept very strong, and the most important resource is kept within multiple layers. I believe this is the right strategy. This provides a high level of database availability and reduces the possibility of direct brute-force attacks against the DBMS. The problem starts when only the initial level of security is used and, as we move through layers, other levels of security are not utilized.
- Data needs to be accessed via objects. Software engineers and the pattern community mostly create this phenomenon. I’ll explain the problem. Here are a few statements that most good software engineers have engraved in their minds:
- Cleanly written software should not make data access calls directly through JDBC/ODBC.
- Data access calls should be dealt with through the data access components/layer.
- Objects should encapsulate the data access functionality, and objects and functionality are secured rather than the underlying data.
- Application business programmers need to be concerned with business objects and should not know where the data resides.
- A SQL statement right in the middle of code is a non-classic way of writing code.
- Data access objects are responsible for knowing how data is stored, and data access objects need to serve business objects.
There is no doubt that all of these statements about code cleanliness are right. However, they all implicitly require a move away from database authentication.
- SQL is easy but not for every developer. When it comes to selecting between a full outer join and a left outer join, 50 percent of the developer population tends to be clueless. SQL incorporation in code is error-prone and requires tedious string parsing. Thus, there is a tendency to avoid SQL statements by writing them once in data access objects and utilizing this object in business objects. Some people have gone to the extreme of defining a separate query language for Enterprise JavaBeans. All this leads to moving the DBMS layer far apart from where authentication and authorization is happening. Developers and administrators tend to secure the data access objects rather than the mechanism to access data.
- Passing user credentials to the DBMS every time is hard. There are at least three problems with passing user credentials to the DBMS from the application layer:
- You need to keep user credentials, including the password, in application sessions all the time.
- Speed ramifications: Opening a database connection is expensive every time and code gets cluttered with not only data access code but connection instantiation code as well. Connection pooling provides these services seamlessly.
- Developers need to send a user name and password at least once a session, and then follow the connection object or send the user name and password over and over. In today’s stateless applications, adding connections to server-side session objects becomes very expensive.
So instead, developers secure the objects with non-database layer security and do not create new connections as new users come in.
- Secure one user only approach. With this approach, database security is pretty trivial to set. Give all access to one user: nobleman; password: trustme1, and voilà!
- Licensing cost. This used to be one benefit of this framework, but database vendors are becoming smart. Now DBMS vendors offer per-server licenses and require a license for any user that is known to the application layer.
- Scalability. I believe this is another big reason for this trend. Making a new database connection is expensive, in terms of programming. Creating a new connection, while a user is waiting for a response, takes time and other resources. Connection pooling provides the option to utilize preinstantiated connections, thus reducing the time for creating new connections.
Also, keeping database connections open has some resource overhead. If applications create a unique connection for each user, then these connections stay idle for most of the time because each connection would be used exclusively for one user. In multitier architectures, a single connection may be serving one user in one fraction of a second and another user in the next fraction of a second. This approach reduces the number of open connections required for applications to maintain. A minimum number of connections is used at any given time with this approach, which increases the scalability options for an application.
Problems With Non-Database Layer Security
With all this information in hand, let’s review the issues with a non-database layer security architecture:
Privacy: Legislation requires maintaining the privacy of collected user data. With this architecture, the DBMS cannot perform data access logging accurately and completely because the DBMS does not know who is actually accessing data. Consequently, the application or data access layer usually does the access logging. If data is dispensed at a lower level and logging is done at an upper level, then there is no way that a true log of data access can be provided. In Figure 1 (above), an organization-internal employee can utilize Nobleman’s user name credential on a PC to get direct access to data without logging being incurred. When the time comes for data access logging, access logging needs to be tightly coupled with access of data, which is not the case with this architecture.
Reinventing proven security in the application layer: Java and other application servers are not fully equipped with data security tools. The DBMS used to take care of this, so that application servers were mostly concerned with providing application object security. Multitier application developers use this object security to fulfill data security needs as well. Now, application servers are trying to provide data security services too, but it will take time to reinvent comparable data security services. At the very best, these security features will not be able to take the place of security at the source, that is, the DBMS level.
Weakest link, one user name and password: With this architecture, database access is limited to a number of generic user names and passwords—most of the time only one. So all a person needs is this user name and password to be able to compromise the integrity of all application data. Those who know this user name/password and are willing to use this aside from the application can get to the database without the knowledge of anyone in the organization. This vulnerability provides a single point of compromise for application data security.
Generic user name and password are guarded with a retinal scan: If this user name and password are very important, then they must be guarded pretty heavily. Wrong!! Multitier applications serve users 24 hours a day, seven days a week. Administrators of these applications make them soft configurable so that if an application dies, a single auto-restart automatically brings it up again. This capability requires storing these user names and passwords in configuration (.ini/.xml) files so that the server can reinstantiate connections after reboot. In a Java implementation, these files will be called something like “config.xml” or “application.properties.” Sometimes, these passwords will be stored in the file system DSN. Most of the time, anyone who breaks in or otherwise gains access to the application server can get access to these files easily. There, one can see these user names and passwords in plain text.
Another important related issue is that if such important user name/password information is floating around in text files visible to system administrators and application developers, how one can guarantee data integrity?
Generic user name and password combination is not frequently changed: The generic user name and password are usually hand-coded into different soft configuration files and thus change in the password does not usually follow corporate password expiry policy. Since the password doesn’t get changed often, it tends to be a static password, and as time goes by more and more administrators learn it. Application server administrators are not an easy-to-find commodity; thus they are usually hired as consultants to set up the application server. They take with them this knowledge of user name and password combinations. As stated earlier, the single user name and password combination is a weak link in this architecture and changing it frequently should be required.
The threat is more severe with internal employees: Gartner Research suggests that a large number of security breaches originate from within organizations. If employees can get physical/network access to the application server, then they can pretty much get access to the configuration files with password info, and in turn, they can change data without anyone’s knowledge.
Triggers are not “tigers” anymore: DBMS triggers are small pieces of code that get executed, behind the scene, any time a change in data occurs. A DBMS can stop the change if a certain criterion is not met. These triggers can diligently log all the data changes to a logging table without a user knowing. DBMS triggers used to be one way to implement any difficult security rule or logging requirement. For example, one can prohibit Mr. White from changing records for Mrs. White on the third Sunday of May between 12:30 am and 1:30 am with a few lines of code in a central location for a table. This rule can be implemented at the application level as well, with some pain, but there will always be a way to overcome it, because someone can directly access the database and not go through the application layer, leaving all the application layer security functionality unused. Triggers are mostly used to log application access-related info, but with multitier architecture, triggers cannot be used to implement data security features and logging mechanisms. Data access logging has been especially compromised because of this approach. No one can now be completely sure that what is shown as a data access log is really a 100 percent data access log.
Security log manipulation Applications do a lot of application security level logging. This includes such things as signature hash storage. In some cases, a little change in this data can produce a big problem for an organization. For example, an administrator can go directly to a signature hash table and delete a signature hash of a senior executive. The nonexistence of a signature hash value can invalidate a previously signed document’s authenticity.
Data access logging is an object-level task: Data access logging is currently done at the object level. Since objects are hosted in the application layer, direct data access cannot be logged. The access logs that are provided to us are just a one-sided story. These logs do not and cannot provide information about 100 percent of true database access. This is not an adequate way to provide data access logging.
DBMSes can provide logging that is 100 percent accurate along with data security features that are completely reliable only because this is where the data is stored, this is the place the data will go out first from, and this is the place everyone has to come to ask for data.
There is no layer in between the DBMS and the data. No mediator is involved in this type of database security and logging mechanism. If logging and access are controlled at the DBMS level, then we can be completely sure that we get accurate data access logging and we can keep data secure.
Best Practices With Multitier Architectures
There is no simple solution to provide data access accountability and data integrity with current multitier architectures. If an organization elects to stay with an existing multitier framework, then I recommend following a few best practices to reduce data integrity risks.
- Application developers need to think through the trade-offs among scalability, security and code maintainability and pick the right mix for their environment. The ideal solution may not be a piece of art, but it may be what an environment needs.
- Developers need to build security measures into databases. They need to intertwine triggers and other measures in their solutions and not completely depend on object security. They need to use more DBMS security for data.
- Try to keep passwords secure and apply all password-related generic good practices.
- Keep passwords encrypted in all places, including soft configuration files. A low-level encryption algorithm like TEA is much better than plain text.
- Keep changing passwords and have scripted mechanisms to move these changes easily.
- Use role-based multiple generic users instead of using one big, hungry user; use multiple users with job roles in mind. Compartmentalize data access with these different users, so if one password is compromised, the whole database doesn’t get compromised.
- It is critical that communication links between the application server and the database server are encrypted. Encryption may slow the application a little, but it will prevent data sniffing issues and potentially reduce major data security vulnerabilities.
- It is strongly recommended to have a Z-out process between database logs and application logs. (“Z-out” processes are used by retail stores to zero out differences between the cash register total and the cash-in-hand total. The cash register prints a total of the day, and the cashier matches this total with the cash in hand. If both have zero difference, then the day’s sale is “Z’d out.”) Once implemented, periodically check to see if there is a difference between the total amounts of data accessed by one layer and another. This mechanism will not tell you who is wrongfully accessing the data, but it will tell you if someone else besides the application layer has been accessing the data.
In this article, I’ve attempted to shed some light on multitier architecture issues so that DBMS vendors, application developers and application server vendors can build the right data security tool and give more thought to data security with application servers.
There are many excellent reasons for the way data security is configured right now, but as I said, providing data access accountability and data integrity with current multitier architectures is a formidable challenge. Future research can be done to explore ways to implement new technologies to keep utilizing existing architecture while fulfilling data integrity requirements.
About the Author
Anis Siddiqy