“We can Improve the Software Itself (And, possibly, the testing) Or We can Improve The Development Process.”
We can improve software development in two primary ways: we can improve the software itself (and, possibly, the testing) or we can improve the development process. We have already covered the preceding three Six Sigma Phases (Define, Measure, and Analyze) in previous articles. Now we take what we have learned and use that information to improve our software development.
Improving the Software Itself
Training software developers is one obvious method for improving software development. All people may be created equal, but not all programmers are equal. However, simply saying ‘training’ isn’t really good enough. We need to consider what our measurement and analysis phases have told us about our software issues. One typical suite of training classes might include the following for a hypothetical embedded software development group (‘Our-Department’):
- Introduction to Our-Department coding practices and standard for the C language
- In-circuit emulation
- Pitfalls in C and how to avoid them
- Our Department specific software handling procedures
- Memory mapping the processor
- Use of static testers n Lessons learned review
- Use of dynamic testers
- Design architectures
We call it ‘training’ but, to some extent, we are really talking about indoctrination into our organization’s practices for software development. Some of these practices will fall under the heading of lessons learned— where we have captured failures from the past as well as solutions to those failures. It does not do much good to critique failures and understand them if there is no learning from this review. Yet, in our experience, this is often what really happens. Frequent reviews of our lessons learned file or database by the entire team is not wasted time. We have seen what we call the ‘stupidity loop’—a phenomenon often tied into the turnover rate of developers, especially with senior developers. We can detect the duration of the stupidity loop by the regularity with which we see the same mistakes begin to recur. Hence, the reviews of the lessons learned file allow our entire team to learn from the past without necessarily having all the original players present.
This important tool can be quite difficult to implement well. While it is easy to list and document the lesson learned, it is not so easy to put this information into a format that makes for easy searching and retrieval. It is the retrieval that is important. We have seen lessons learned documented in word processors, spreadsheets, databases, and free-form storage (for example, Microsoft OneNote). Even with a database, we need to have a good system of search categories and terms or nobody will be able to retrieve the information promptly. If the work to review the lessons becomes a burden, the task will starve away and we will have lost an opportunity to profit from past blunders. If we are using textual information, we can use search engines like Google Desktop to help us find information; an older approach using ASCII files would involve the use of the grep tool common on UNIX-types of operating systems. Once retrieval becomes efficient, we have the beginnings of defect prevention program. We don’t think it is inappropriate to make the use of the lessons learned database a part of the software engineer’s performance evaluation.
In a sense, while we call it training, what we are really talking about is a continually learning organization(1) . This is more than learning from the failures. This includes boundary spanning for best practices, which is not necessarily a euphemism for procuring the best practices of other organizations. We may also be able to affect the software development process by benchmarking our own organizational practices against those of a well-reputed software house with who we are not in competition. The benchmarking exercise should provide ideas for testing in our own organization (note: we test because many times, the ideas of other organizations are not simply drop-in practices).
For developers not in the embedded software arena, the same kind of approach applies. We want to capture what we think the developers need to know and we want to indoctrinate the team regarding known development issues that have occurred before. This indoctrination includes instilling the organization’s risk philosophy and extends to why some things are done the way they are done; in short, we describe our practice and how to perform them as well as the rationale for doing it that way. The approach applies regardless of whether we are looking at web development, enterprise applications, or database management.
In addition to indoctrination/ training, we can also reuse known good code as long as we spell out the rules for doing so. In fact, reuse of code (and pieces of hardware for that matter) can become another topic for the training part of software improvement. For code reuse to work well, the library modules we are going to reuse must be well documented and, well, modular. In some cases, these components can exist as executable code in the form of dynamic link libraries; in other cases, we may have to incorporate source code into our new source code (definitely less desirable since this approach can lead to degradation if the developers touch the library code). As we already know, some languages lend themselves to modularity better than others.
Encapsulation (or decoupling) is often a language-based approach to implementing good practices, although we can accomplish decoupling by focusing our attention on older languages that do not explicitly support it. If we can encapsulate a software object such that access to its methods is well-controlled we increase the likelihood of producing a truly robust module. We can practice encapsulation with any language, although the truly object-oriented languages help us to enforce these practices. We also want to be sure that our code will check for simple flaws like overflows and underflows—we can’t expect the run-time produced by the compiler/linker to do this for us. With embedded code, we must make sure we are not burdening the microcontroller excessively while maintaining the safety of our code (a sad truth sometimes). The more risky the result of an over- or underflow, the more important the practice of deliberate protection will be. We have seen substantial protection written into code that controlled a fighter aircraft since the results of a failure were likely to be catastrophic. The approach worked well.
Improving the Software Testing
We recommend a MuLTiModaL approach to testing, particularly if our measurement and analysis phases suggest that we are letting defects through to our customers.
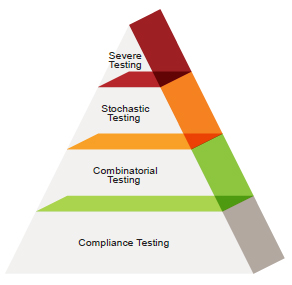
In general, in the embedded world, we use the following approaches most often:
- Compliance testing: testing to the requirements specification
- Combinatorial testing: wherein we stimulate the inputs of the system and observe the outputs of the system using a recipe that exercises all inputs in a particular pattern (for example, pairwise testing tests all pairs)
- Stochastic testing (or exploratory): we allow the test engineer to use their ‘gut’ and knowledge of the product to explore the behavioral envelope of the software; sometimes, we can use tools to help with this approach (for example, a genetic algorithm)
- Severe testing: we challenge the software by doing horrible things to the data bus, the input values, the hardware—anything goes with this kind of testing. This testing can exceed the design limits to ferret out marginal performance issues. In fact, it is not out of line for the testing to go all the way to the destruct limit—by so doing, we establish the true design limit, the failure limit, and the destruct limit, thus characterizing the product.
Occasionally, an approach like severe testing will produce specious failures; that is, failure we would never expect to see in the field. However, any failure indicates some kind of weakness in the code. We can then make a conscious decision whether or not we should take action on this failure information. This is much better than not looking at what the risk may be; furthermore, in the unlikely event we do see these failures in the field, we already know something about them and have a remedy prepared in anticipation of these dire consequences.
Test suites can be just as reusable as reusable software. In fact, for regression testing (testing to verify we haven’t added defects to already good code); we want to reuse the previous collection of tests to perform our regression testing. Our Six Sigma measurement and analysis phases will tell us if the regression testing performs up to expectations. This is a good candidate for automation, especially for organizations that have an iterative product development methodology. In electronics product manufacturing facilities, it is not uncommon to see automated test equipment that is used to exercise the product; in effect, performing extremely high-speed regression tests. We recommend the same kind of approach to regression testing—using technology to speed us through the tedium of ensuring we did not decrease the quality of the software.
We can use the results of exploratory testing to add to our existing set of formal tests; in effect, practicing continuous improvement with our test suite. Consequently, we can expect the test suite for a specific product to grow as we move through the development project—we are learning about the product as we proceed. The expansion of the test suite should be welcomed rather than rejected because it allows us to tighten down on the product with every iteration of the test suite and each release. An additional benefit of the regular growth of the test suite is that the testing becomes more stringent as we move towards release of our software.
Test automation can improve our situation by taking our test suite and applying it to the product at machine speeds as we have already mentioned in our section regression testing. An additional benefit arises because we often do not have to have any kind of human intervention and we can, therefore, run our test suite day and night, thereby improving our throughput on test case achievement. In our case, we are also set up to make a video recording of the testing for subsequent review in the case of a logged failure. Sometimes automation may not be practical for a specific product, but we recommend automation whenever possible.
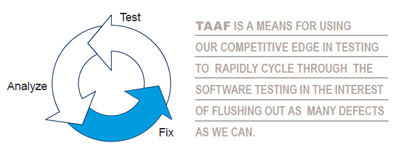
The automation, partially or fully, of a test suite allows our test engineers and the software engineers to move towards a test, analyze, and fix (TAAF) regime. TAAF is a means for using our competitive edge in testing to rapidly cycle through the software testing in the interest of flushing out as many defects as we can. We continue to measure defect arrival rates and, when feasible, we can compare our results to a Rayleigh model, which may provide us with a statistical basis for authorizing a release of a product.
Improving the Software Development Process
Prioritizing tasks can be difficult, especially when our team is under the hammer to deliver promptly (everything and now). Because many myths surround a highly-cognitive field like software engineering, it can be difficult to determine what the highest priorities are. For example, some organizations find complete and comprehensive requirements document far outweighs the benefits of design documentation. Other organizations may find or believe the reverse.
Additionally, we can use some simple financial tools to help us prioritize the tasks within our development process. We have used a tool that combines net present value with some qualitative assessments and provides a quick pseudo-quantitative calculation of priorities. When mixing factor types, we need to be careful that the value from the NPV calculation does not swamp the qualitative data.
We can usually detect a prioritizing issue when we hear our engineers say something like “I couldn’t do the frimfram function because I didn’t have time.”
Product development process knowledge of the staff is particularly helpful. We are not talking about the knowledge of the players for their particular part of the development puzzle, but knowledge of how the pieces should go together in general. Colleges and universities teach engineers, both hardware, and software, about the technical details of the development process. Something as rudimentary as configuration management needs are usually not covered and certainly, the role of product testing is not. The staff’s knowledge of the entire puzzle can come from the use of well-defined software architecture document. The architecture document, if well-crafted, will often see little modification during the development of the software; yet, it is the foundation for understanding the puzzle and all the pieces as a whole. This document can be a key reference when modifications become necessary as new features are required or fixes need to be made.
Design tools can be helpful, particularly when it is possible to produce usable code directly from the design tool. We know for example, that the International Telecommunications Union standards Z.100, Z.105, and Z.120 have been implemented in software by Telelogic. This design software produces pseudocode and a graphical representation simultaneously during the software design phase. The code can be tested within the design tool and, when it is ready for outside-the-tool testing, the design can be compiled directly. Other tools such as Matlab/ Simulink from Mathworks have similar capabilities.
Design tools that are decoupled enough from the code such that they cannot either produce code or a compiled image are generally less useful, although we have seen research indicating that the effort of working in the latest version of the Universal Modeling Language (UML) produced software with fewer issues than similar software developed without the discipline of presenting the design in an abstract format. We need to use these tools with care so that they don’t become a collection of pretty pictures to dazzle the customer and upper management. Any reasonably competent modeling tool actually represents a grammar; hence, the structure of the model should be verifiable electronically. If this feature is not available, the results from the design tool will be palliative but not corrective.
Design reviews are often touted as a means for improving software. Our experience suggests that reviews may be useful if the participants approach the presented design as if they were hungry piranha and the design was a piece of fresh meat. A design review that doesn’t have metaphoric blood flowing under the door probably isn’t accomplishing much. The primary issue with this approach can be tied to the following items:
- Lack of use of measurement
and analysis information - Failure to use the lessons
learned file - Inadequate critiques from the
participants (the critique should
not start when the actual review
starts – come prepared) - Lack of interest or time put
in up front for the review
For design reviews to have any chance of having an impact on the end design result, the due diligence in the critique has to be greater than the due diligence during the design work. The consequences for taking this review lightly should have some impact on the reviewers. Having people showing up with marked up copies of the design – should be a requirement. Those that do not perform this upfront work, have not delivered and are evaluated accordingly.
Unfortunately, these items suggest that design reviews are hardly deterministic and may have significant qualitative issues. It is when looking back over your shoulder that you notice that a particular failure should have / could have been caught had there been a critical design review. One potential method for improving the design review would be to start with a standardized checklist based, in part, on our lessons learned documentation. At a minimum, this approach will provide a basis for starting the review as well as providing a baseline for problem-checking.
Proof of correctness is a rarely used technique, yet a powerful approach to software development. When we prove that software is correct, we assume the specified requirements are themselves correct by some definition of correctness. The requirements may be expressed in a formal language such as Z or the B-Method or some other systematic approach. The requirements are really the Achilles heel of this process. Extensive documentation does not necessarily help. There is still much interpretation by multiple parties, common understandings are more difficult to reach, and we may think a common understanding of the documentation exists when such is not the case. Computer scientists have theorized about formal methods for years and both the U.S. Department of Defense and NASA have taken a look at the usefulness of the approach, particularly with safety-critical software. The difficulty of the approach has always been the level of mathematical and logical sophistication required.
Once we have the code, we can derive the coherence of that code against the requirements. We do not need a doctorate in symbolic logic to be able to do this, but we do need to have a fundamental idea of how to approach the correctness problem. Even so, the correctness approach has the benefit of being less qualitative and more stringent than the design review approach.
Increasing tempo helps us especially when we are trying to implement a TAAF (Test, Analyze, And Fix) regimen to our testing and software development. From the project management perspective, we might implement scrum as a simple means of accelerating development and improving project oversight. We have used scrum for line management and we know from experience that the scrum approach will improve the cadence of accomplishment.
We can take scrum to the next step and implement a Kanban system. In the Kanban approach, we will take all of our user stories (or functions or features) and break them into ‘bite-size’ chunks. We can then put these items on an electronic whiteboard or a real one and ask the developers to pull the feature from the setup area to the work area to be followed by the complete area when this discrete portion of the project is now complete. The Kanban approach is excellent for job release to the developers but may make for headaches with the planners. The solution to the planning issue lies with reasonably accurate estimation of the work time for each Kanban card/ticket.
Regardless of which choices we make, the software development process must be measured: first, to be sure we didn’t make it worse and, second, to ensure we have a detectable improvement in performance.
Conclusion and Next Step
There are many ways to improve the quality of the development deliverables. You must start with an understanding of your problem areas and where you can do the most good with the least effort. Making changes to the design environment also means understanding the variables, particularly those that are directly changing because of the improvement actions. These variables we will have derived from the measurement and analyze phases of our Six Sigma problem-solving approach. This means keeping your eyes open for the unintended consequences. The next time we will discuss: Control – the approaches we use to make our improvements sustainable.
About the Authors:
Jon Quigley Jon M. Quigley PMP CTFL is a principal and founding member of Value Transformation, a product development training and cost improvement organization established in 2009, as well as being Electrical / Electronic Process Manager at Volvo Trucks North America. Jon has an Engineering Degree from the University of North Carolina at Charlotte, and two Master Degrees from the City University of Seattle. Jon has nearly twenty-five years of product development experience, ranging from embedded hardware and software through verification and project management.
Kim Pries Consultant principal, Director of Product Integrity and Reliability, Software Manager, Software engineer, author (books and magazine articles), DoD contractor and much more. 7 national certifications in production/inventory control and quality and 4 college degrees.