Even Troglodytes Can Understand Automation with This Framework Approach
Test automation typically relies on a select group of technical people within the QA organization for development and maintenance. This dependence can be magnified when an automation framework is used. Although beneficial, frameworks can make it difficult to involve non-technical staff effectively in the automation process.
What’s needed—and what we’ve developed—is an automation framework approach that is suited to bridging this gap. Our approach captures both test data and test logic in a format that’s easily managed and consumed by both technical and non-technical personnel.
This increases the QA staff’s ability to actively participate in the automation process, decreasing the time required for automation projects. At the same time, fundamental elements of modularity and data reuse required to support a robust, low-maintenance automation solution are fully realized.
What’s Required
A key challenge for software test automation is determining how to automate hundreds or even thousands of existing manual test cases in a relatively short time frame without introducing too much maintenance overhead.
Simple record and playback attempts often fail because of their inherent disorganization and ever-increasing maintenance demands over time. Using a function-based approach requires less maintenance, but introduces new complexities and severely reduces the ability of non-technical personnel to participate in the process. An action/keyword-driven approach opens the automation to staff outside the technical circle, but requires significant overhead in documentation, management and coordination to keep the growing system from falling into disarray.
This article presents a framework-based approach to automation that is superior to these common strategies. This intuitive methodology implements results in a well-organized, scalable framework that serves as a strong foundation for automation efforts. Maintenance is minimized as a result of high code and data reuse.
In this data-driven approach, both the test data and logic are captured in a logical, organized manner that enables non-technical staff to make significant contributions, increasing the practical capacity available to build up the automation.
Modular and Data-Driven
To accomplish a task in an application, a user typically follows a specific set of steps in a specific sequence with specific input—commonly referred to as a workflow. For this article, we’ll focus on a simple workflow of deficiency analysis in the context of an electronic patient record–management system.
In a medical setting, a complete chart without deficiencies is a requirement for billing. A deficiency analyst is responsible for checking patients’ medical records for completeness and for adding markers to patients’ charts to indicate deficiencies.
To test this workflow, we incorporated the creation of a chart with documents on which deficiency markers are placed. Basic workflow is:
Create Patient Record ? Add Documents to Patient Record ? Add Deficiencies
For each of these three unique activities, a step-level driver function is created. In this case, the following functions are created:
CreatePatientRecord()
AddDocument()
AddDeficiency()
We refer to these drivers as modules. They’ll become the key building blocks for our test cases in this approach. Similarly, other modules can be created for other functionalities of the medical record system to complete deficiencies, edit documents, send messages and perform other tasks. Each module should be designed to handle both positive and negative cases, with appropriate exception handling, since the collection of these modules will provide the foundation for building automated test coverage across the entire area of deficiency analysis.
To test the workflow identified, the developed modules must be executed in sequence. This sequence of execution requires a reliable transition from the final state of one module to the beginning state of the next. Either transition states must be stored and transferred across modules or all modules must return to a common state. We chose the latter approach.
For simple applications, we developed all modules to return to a single common landing page. Generally, the log-in page or the first page after logging into the application is a good choice. For more complex applications, a landing page can be selected for each major area of functionality and used in similar fashion.
Once processing is completed for each area, execution returns to the general application landing page—again, most likely a log-in or home page in the application. While the landing-page approach may introduce some extra motion compared to managing transition states, we’ve found it to be reliable, easy to maintain and easy to apply across all modules.
Data Separate From Code
Each module is responsible for processing data required to accomplish its designed purpose within the application under test (AUT). For example, the CreatePatientRecord() function will:
- Read in data from an Excel spreadsheet in a data table
- Navigate to the Add Patient page
- Fill in corresponding fields on the Add Patient page
- Click the Save button to create a new patient record
- Verify patient created or not created, depending on the test being performed
Data and code are separated in this design. Test data is always contained in data tables, never directly coded in module functions. Changes to the underlying code can be made transparently, so long as the data is still processed according to test needs. Similarly, the data content can be varied and even extended to meet new test requirements.
After creating the modules to support the automation of various workflows, a means must be supplied to combine these workflows to meet general test objectives. Consistent with this framework’s data-driven approach, a top-level master data table is created to pull together all areas of test. This table is referred to as the test case manager. A generic top-level driver script is also created to process this table, directing test-case execution to execute desired processing modules, according to the data table.
Next, let’s examine the relationship among data tables and the rules governing their format.
Data Table Structure and Rules
Data consumed by this automation framework is provided in Excel spreadsheets referred to as data tables. They obey the following rules:
Overall data table structure is two (or three at most) tiers deep.
- The two-tier structure has a master data table and a single layer of referenced child data tables. This is the recommended approach unless a specific need is identified to introduce the three-tier structure.
- For a three-tier structure, a child data table may reference another, deeper-level child table. This is generally done to reduce overall complexity of the tables, or to group together common data sets (for example, detailed patient information) that are reused across multiple tasks within an area.
The master data table (or test case manager) defines tasks to be performed for test cases (see the master data table in Table 1 below).
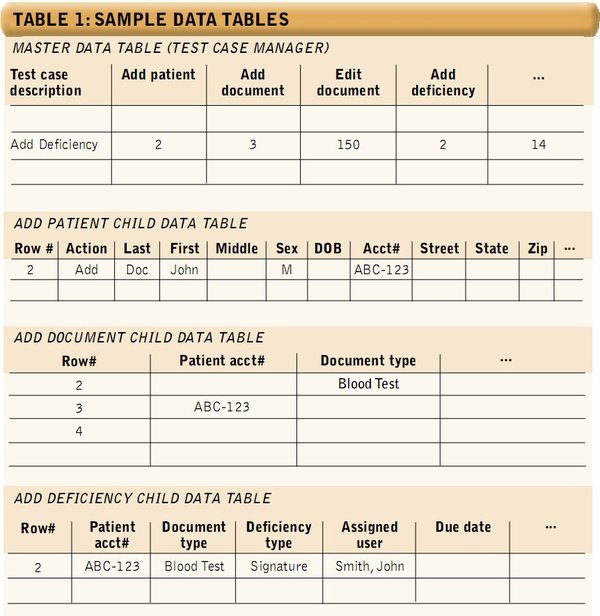
- Generally, each row in the master data table is a test case. A test case is defined by a series of tasks. These tasks must be performed in order from left to right as they appear on the spreadsheet. If a test case needs to complete a task from a right column first, it only has to be split into two or more rows.
- Each column of the master data table maps to a child data table through the column header. In general, all child data tables are contained in same workbook as the master. Each child data table contains detailed data needed to complete a specific task.
Master data table processing occurs according to the following:
- A single row is parsed from left to right by underlying driver function.
- When data is encountered in a cell, the associated task (identified by column header) is executed.
- Generally, a single number serves as a reference to identify a specific row in the child data table to be processed. However, a range reference or metadata can be included, so long as the underlying module supports parsing of the data type.
- If a cell is empty, the associated task isn’t executed, and processing moves to the cell to the immediate right.
Each child data table contains data used to perform a specific task; for example, adding a patient (see the Add Patient Child data table in Table 1 above).
- Usually, each column on a child table maps to a field on a specific page within the application under test, or to a practical action to be taken on a page. For example, the Add Patient data table has an Action column to indicate whether to add a new patient or edit an existing one, since the same window is being used for both purposes.
- Each row contains the required data to accomplish a task in the application. This may include validation data, notes, etc. Additionally, a child data table may drive processing across multiple pages in the AUT—this can help to reduce the number of data tables when data from multiple pages is needed for a task and the amount on each page isn’t very large.
- A driver function must be created for each child data table to process the data. This function is also responsible for bringing up the page to which the child data table is mapped and setting the application to the common landing page after processing the data.
A Practical Example
FIGURE 1: MASTER TABLE PROCESSOR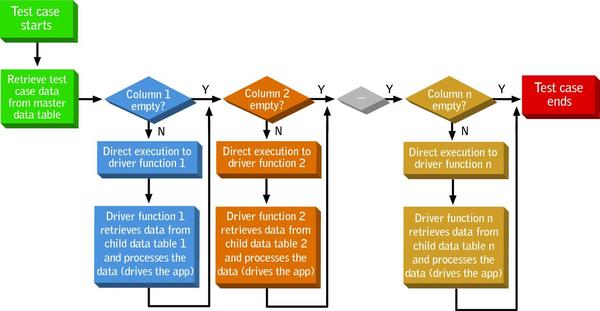
Using our automation tool, we created a master driver function to process the data in the master data table. This high-level driver function requires practically no business intelligence and has a robust recovery system to set the application to the ready state in case of test case failure. It operates as shown in Figure 1 above. Figure 2 below illustrates tracing through the driver processing for the data tables in Table 1 above.
FIGURE 2: TEST CASE EXECUTION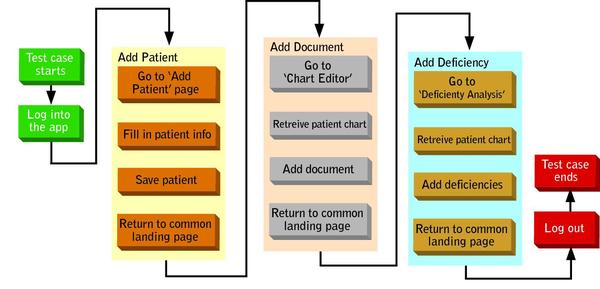
Benefits of the Approach
This approach yields a framework model that is intuitive to design, build and maintain. Well-designed data tables not only organize the system, but provide an element of self-documentation. Separation of code and data offers a layer of abstraction that increases the underlying code’s flexibility and resilience. High code reuse at the module level further minimizes maintenance. Many places in the system are appropriate for generic or template-based approaches, further extending the ability to reuse code and data.
With this approach, domain engineers (manual testers, business analysts, etc.) can play a substantial role in the design and build-out of test automation assets. With top-level processing logic and test data contained in easily accessible Excel spreadsheets, we can now tap the knowledge of these engineers practically. This provides a tangible boost to resource capacity available to build the automation and further ensures that automated tests accurately reflect test intentions. Our experience indicates that such personnel were able to independently create and execute tests after only a four-hour training session.
This approach can be scaled to meet a variety of test needs. A minimal framework can be created quickly to cover a small application or specific area of a larger system. In this case, all data sheets can be designed and contained in a single compact workbook; or a specific test need, such as boundary testing, can be met with minimal adaptations. Best of all, this approach has proven practical for large-scale automation—across all areas of complex applications, and even across system boundaries.
About the Author
Robert Carlson ROBERT CARLSON is manager of test automation and load/performance testing at MedPlus. He has been involved with software quality since 1995, and was involved in the design, implementation, support and build-out of various automation approaches across multiple technologies and industries.