
It starts with a bug- an invisible bug that turns one user’s experience into a long and painful waiting game that usually ends badly. If only they had called tin the Performance Police.
The deadline’s Friday. This Friday. That’s when this baby goes live; when the huddled masses from this naked city and others across the globe descend on our creation. Our baby, that we nurtured from conception to the day it was born.
What was my part in all this? Nothing major. Just to make sure this crackling cacophony of code was ready for prime time; that it doesn’t go belly-up when the pounding starts. When the throngs of ravenous consumers are unleashed on our servers. People. Users. Tired, hungry, angry and bored by monotonous life on the streets and looking for an escape, a way out, out of their tedious existence.
But I’m not worried. I had a plan. A plan I’d put into place on day one of this project. Because performance, load and reliability bugs can really hurt. Inadequate performance can lead to user dissatisfaction, user errors and lost business, especially in Internet-based, business-to-business or business-to-consumer applications.
Further, system failure under load often means a total loss of system functionality, right when need is highest—when those throngs are banging away on your system.
Reliability problems also can damage your company’s reputation and business prospects, especially when money is involved.
I’ve worked in software testing for the last 20 years, and many of the projects I’ve done included performance, load or reliability tests. Such tests tend to be complex and expensive compared to, say, testing for functionality, compatibility or usability.
When preparing a product for deployment, one key question to ask is, “Are you sure there are no critical risks to your business that arise from potential performance, load or reliability problems?” For many applications these days, such risks are rampant.
Abandoned Shopping Carts, Degraded Servers
For example, let’s say you were running an e-commerce business and 10 percent of your customers abandoned their shopping cart due to sluggish performance. How can you be sure that customers who’ve had a bad experience will bother to come back? Can your company stay in business while hemorrhaging customers this way?
A colleague once told me that he had just finished a project for a banking client, during which the bank estimated its average cost of field failure was more than $100,000. That was the average; some failures would be more expensive, and many were related to performance, load or reliability bugs.
Some might remember the Victoria’s Secret 1999 online holiday lingerie show, a bleeding-edge idea at that time. This was a good concept—timed propitiously right at the Christmas shopping season—but poorly executed. Their servers just couldn’t handle the load. And worse, they degraded gracelessly: As the load exceeded limits, new viewers were still allowed to connect, slowing everyone’s video feeds to a standstill.
In a grimmer example, a few years ago, a new 999 emergency phone service was introduced in the United Kingdom. On introduction, it suffered from reliability (and other) problems, resulting in late ambulance arrivals and tragic fatalities. All of these debacles could have been avoided with performance, load and reliability testing.
Hard-Won Lessons
Like any complex and expensive endeavor, there are many ways to screw up a performance, load or reliability test. Based on my experience, you can avoid common goofs in five key ways:
- Configure performance, load and reliability test environments to resemble production as closely as possible, and know where test and production environments differ.
- Generate loads and transactions that model varied real-world scenarios.
- Test the tests with models and simulations, and vice versa.
- Invest in the right tools, but don’t waste money.
- Start modeling, simulation and testing during design, and continue throughout the life cycle.
I’ve learned these hard-won lessons through personal experience with successful projects, as well as expensive project failures. All of the case studies and figures are real (with a few identifying details omitted), thanks to the kind permission of my clients. Let’s look at each lesson in detail.
PEOPLE COMMONLY bring physical-world metaphors to system engineering and system testing. But software is not physical, and software engineering is not yet like other engineering fields.
For example, our colleagues in civil engineering build bridges from standard components and materials such as rivets, concrete and steel. But software is not yet assembled from standard components to any great extent. Much is still designed and built to purpose, often from purpose-built components.
Our colleagues in aeronautical engineering can build and test scale models of airplanes in wind tunnels. However, they have Bernoulli’s Law and other physical principles that can be used to extrapolate data from scale models to the real world. Software isn’t physical, so physics doesn’t apply.
But the standard rules apply for a few software components. For example, binary trees and normalized relational databases have well-understood performance characteristics. There’s also a fairly reliable rule that once a system resource hits about 80 percent utilization, it starts to saturate and cause non-linear degradation of performance as load increases. However, it’s difficult and, for the most part, unreliable to extrapolate results from smaller environments into larger ones.
In one case of a failed attempt to extrapolate from small test environments, a company built a security management application that supported large, diverse networks. The application gathered, integrated and controlled complex data related to the accounts and other security settings on servers in a managed network.
They ran performance tests in a minimal environment, shown in Figure 1 (below). This environment was adequate for basic functionality and compatibility testing, but it was far smaller than the typical customer data center. After selling the application to one customer with a large, complex network and security data set, the company found that one transaction the customer wanted to run overnight, every night, took 25 hours to complete.
FIGURE 1: REAL PROBLEM–UNREAL SIMULATION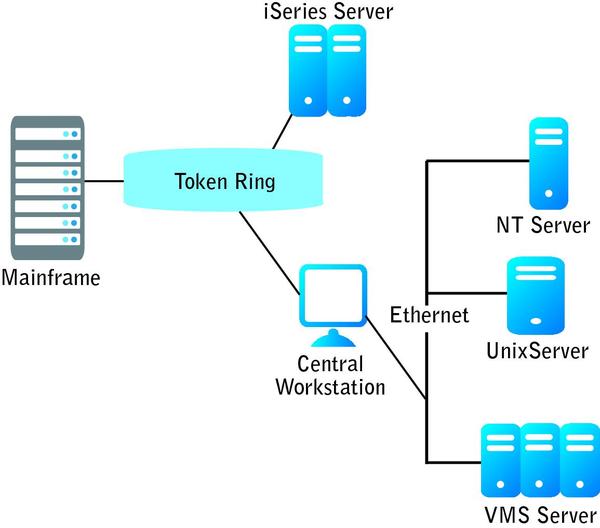
For systems that deal with large data sets, the data is a key component of the test environment. You could test with representative hardware, operating system configurations and cohabitating software, but if you forget the data, your results might be meaningless.
Now for the proper test environment. For a banking application, we built a test environment that mimicked the production environment, as shown in Figure 2 (below). Tests were run in steps, with each step adding 20 users to the load. Tests monitored performance for the beginning of non-linear degradation, the so-called “knees” in the performance curve. Realistic loads were placed on the system from the call-center side of the interface.
FIGURE 2: REAL SOLUTION–REAL WORLD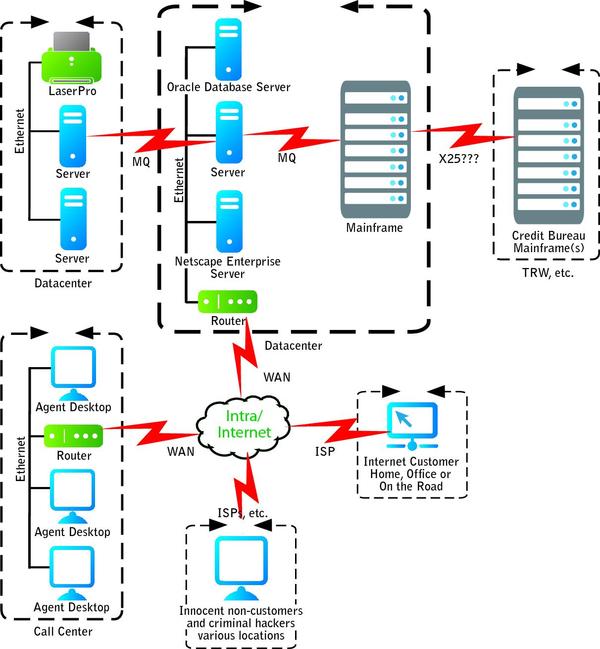
The only differences between the test and production environments, a wide-area network that tied the call center to the data center, were in the bandwidth and throughput limits. We used testing and modeling to ensure that these differences wouldn’t affect the performance, load and reliability results in the production environment. In other words, we made sure that, under real-world conditions, the traffic between call center and data center would never exceed the traffic we were simulating, thus guaranteeing that there was no hidden chokepoint or bottleneck.
To the extent that you can’t completely replicate the actual production environment, be sure that you identify and understand all the differences and how they might affect your results. However, more than two material differences will complicate extrapolation of results to the real world and call the validity of your test results into question.
THE NEXT STEP is to achieve realistic performance, load and reliability testing using realistic transactions, usage profiles and loads. Real-world scenarios should include not just realistic usage under typical conditions, but also factor in the occurrence of regular events. Such events can include backups; time-based peaks and lulls in activity; seasonal events like holiday shopping and year-end closing; different classes of users such as experienced, novice and special-application users; and allowance for growth into the future.
Also, don’t forget about external factors such as constant and variable loads on LAN, WAN and Internet connections, the load imposed by cohabiting applications, and so forth.
Don’t just test to the realistically foreseen limits of load, but rather try what my associates and I like to call “tip-over tests.” These involve increasing load until the system fails. At that point, what you’re doing is both checking for graceful degradation and trying to figure out where the bottlenecks are.
Here’s a case of testing with unrealistic load. One project we worked on involved the development of an interactive voice response server, such as those used in phone banking systems. The server was to support more than 1,000 simultaneous users. A vendor was developing the software for the telephony subsystem. However, during subsystem testing, the vendor’s developers tested the server’s performance by generating load using only half of the telephony cards on the system under test.
Based on a simple inspection of the load-generating software, we discovered that the system load imposed by the load generators was well below that of the telephony software we were testing. We warned the vendor and the client that these test results were meaninglessness, but our warnings were ignored.
So, it was no surprise that the invalid tests “passed,” and as with all false negatives, project participants and stakeholders were given false confidence in the server.
The load generator that we built ran on an identical but separate host system. We loaded all the telephony ports on the system under test with representative inputs. The tests failed, revealing project-threatening design problems, which I’ll discuss later.
The lesson here is to use nonintrusive load generators for most performance testing. The tests executed can stress no more than half the system’s ports since the other half must be reserved for generating the test load. Performance, load and reliability testing of subsystems with inexact settings can yield misleading results.
However, there are some instances of load and reliability testing in which intrusive or self-generated load can work.
A number of years ago, I led a system test team that was testing a distributed Unix application. The system would support a cluster of as many as 31 CPUs, which could be a mix of mainframes and PCs running Unix. For load generators, we built simple Unix/C programs that would use up CPU, memory and disk space resources, as well as generating files, interprocess communication, process migration and other cross-network activities.
The load generators, simple though they were, allowed us to create worst-case scenarios in terms of the amount of resource utilization and the number of simultaneously running programs. No realistically foreseen application mix on the cluster could exceed the load created by those simple programs.
Even better, randomness built into the programs allowed us to create high, spiking, random loads that we sustained for up to 48 hours. We considered it a passing test result if none of the systems crashed, none of the network bridges lost connectivity to either network, no data was lost, and no applications terminated abnormally.
SO NOW IT’S CLEAR that realism of the environment and the load are important. Being complex endeavors, performance, load and reliability testing are easy to screw up, and these two areas of realism are especially easy to screw up.
The key to establishing realism of environment and load before going live is to build a model or simulation of your system’s performance. Use that model or simulation to evaluate the performance of the system during the design phase and evaluate the tests during test execution.
And since the model or simulation is equally subject to error, the tests also can evaluate the models. Furthermore, a model or simulation that is validated through testing is useful for predicting future performance and for doing various kinds of performance “what if” scenarios without having to resort to expensive performance tests as frequently.
Spreadsheets are good for initial performance, load and reliability modeling and design. Once spreadsheets are in place, you can use them as design documents both for the actual system and for a dynamic simulation. The dynamic simulations allow for more what-ifs and are useful during design, implementation and testing.
Here’s a case for using models and simulations properly during the system test–execution period. On an Internet appliance project, we needed to test server-side performance and reliability at projected loads of 25,000, 40,000 and 50,000 devices in the field. In terms of realism, we used a production environment and a realistic load generator, which we built using the development team’s unit testing harnesses.
The test environment, including the load generators and functional and beta test devices, is shown in Figure 3 (below). Allowing some amount of functional and beta testing of the devices during certain carefully selected periods of the performance, load and reliability tests gave the test team and the beta users a realistic sense of user experience under load.
FIGURE 3: INTERNET APPLIANCE PROJECT TEST ENVIRONMENT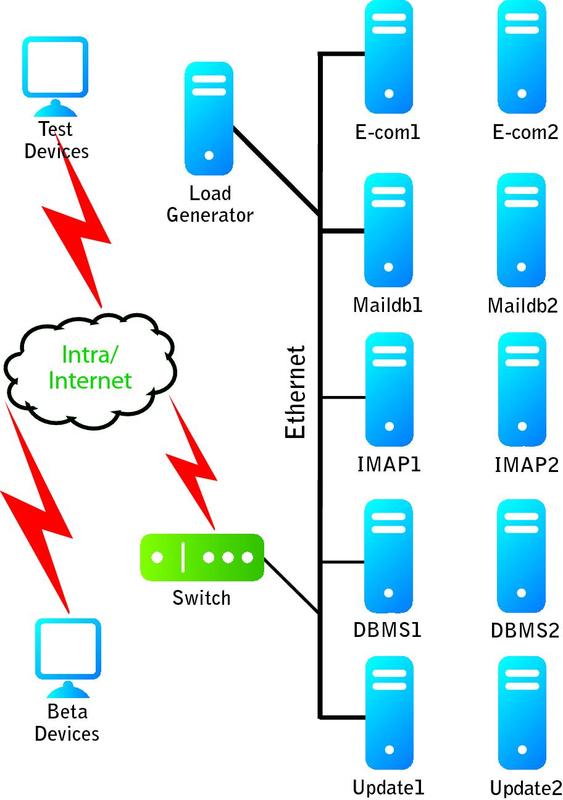
This is all a pretty standard testing procedure. However, it got interesting when a dynamic simulation was built for design and implementation work. We were able to compare our test results against the simulation results at both coarse-grain and fine-grained levels of detail.
Let’s look first at the coarse-grained level of detail, from a simulation data extract of performance, load and reliability test results from the mail servers (IMAP1 and IMAP2 in Figure 3 above). The simulation predicted 55 percent server CPU idleness at 25,000 devices. Table 1 (below) shows the CPU idle statistics under worst-case load profiles, with 25,000 devices. We can see that the test results support the simulation results at 25,000 devices.
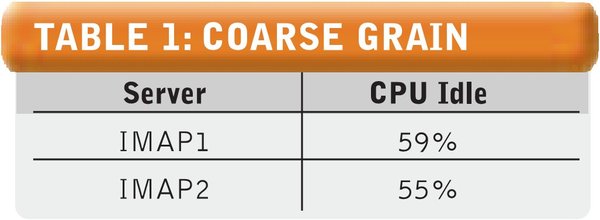
Table 2 (below) shows the fine-grained analysis of the various transactions the IMAP servers had to handle, their frequency-per-connection between the device and the IMAP server, the average time the simulation predicted for the transaction to complete, and the average time that was observed during testing. The times are given in milliseconds.

As you can see, we had good matches with connect and authorize transactions, not a bad match with select transactions, a significant mismatch with banner transactions, and a huge discrepancy with fetch transactions. Analysis of these test results led to the discovery of some significant problems with the simulation model’s load profiles and to significant defects in the mail server configuration.
Based on this case, we learned that it’s important to design your tests and models so that you can compare the results between the two.
AS A GENERAL RULE, tools are necessary for performance, load and reliability testing. Trying to do these tests manually would be difficult at best, and not a best practice, to be sure.
When you think of performance testing tools, one or two might come to mind, along with their large price tags. However, there are many suitable tools, some commercial, some open source and some custom-developed. For complex test situations, you may well need a combination of two or three.
The first lesson when considering tool purchases is to avoid the assumption that you’ll need to buy any particular tool. First, create a high-level design of your performance, load and reliability test system, including test cases, test data and automation strategy.
Second, identify the specific tool requirements and constraints for your test system. Next, assess the tool options to create a short-list of tools. Then hold a set of competitive demos by the various vendors and with the open-source tools. Finally, do a pilot project with the demonstration winner. Only after assessing the results of the pilot should you make a large, long-term investment in any
particular tool.
It’s easy to forget that open source tools don’t have marketing and advertising budgets, so they won’t come looking for you. Neither do they include technical support. Even free tools have associated costs and risks. One risk is that everyone in your test team will use a different performance, load and reliability testing tool, resulting in a Tower of Babel and significant turnover costs.
This exact scenario happened on the interactive voice—response server project, and prevented us from reusing scripts created by the telephony subsystem vendor’s developers because they wouldn’t coordinate with us on the scripting language.
I can’t stress the issue of tool selection mistakes enough; I’ve seen it repeated many, many times.
In another case, a client spoke with tool vendors at a conference and selected a commercial tool based solely on a salesperson’s representations that it would work for them. While conferences are a great place to do competitive feature shopping, such on-the-spot purchasing is usually a bad idea.
They soon realized they couldn’t use the tool because no one on the team had the required skills. A call to the tool vendor’s salesperson brought a recommendation to hire a consultant to automate their tests. That’s not necessarily a bad idea, but they forgot to develop a transition plan or train the staff to maintain tests as they were completed. They also tried to automate an unstable interface, which in this case was the GUI.
After six months, the consultant left and the test team soon found that they couldn’t maintain the tests, couldn’t interpret the results and saw more and more false positives as the graphic user interface evolved. After a short period, the tool was abandoned, wasting the company about $500,000.
Here’s a better way. While working on a complex system of WAN-connected interactive voice response servers linked to a large call center, we carefully designed our test system, then selected our tools using the piloting process described earlier.
We ended up using the following tools:
- QA Partner (now Borland SilkTest) to drive the call-center applications through the graphical user interface
- Custom-built load generators to drive the interactive voice-response server applications
- Custom-built middleware to tie the two sides together and coordinate the testing end-to-end
We used building blocks like the TCL scripting language for our custom-built test components. The overall test system architecture is shown in Figure 4 (below). The total cost of the entire system, including the labor to build it, was less than $500,000, and it provided a complete end-to-end test capability, including performance, load and reliability testing.
FIGURE 4: COMBINING COTS AND OPEN SOURCE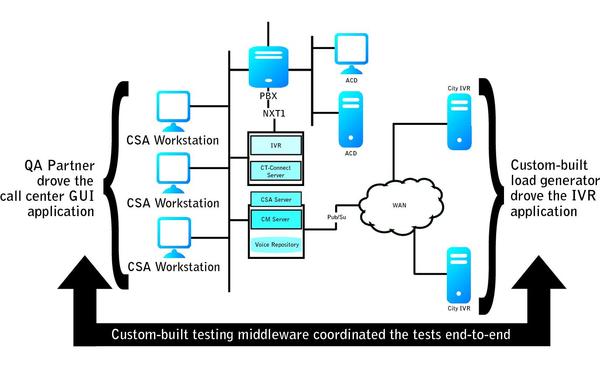
LAST BUT CERTAINLY not least is to begin thinking about and resolving performance, load and reliability problems from day one of the project. Performance, load and reliability problems often arise during the initial system design, when resources, repositories, interfaces and pipes are designed with mismatched or too little bandwidth.
These problems also can creep in when a single bad unit or subsystem affects the performance or reliability of the entire system. Even when interfaces are designed properly during implementation, interface problems between subsystems can arise, creating performance, load and reliability problems.
Slow, brittle and unreliable system architectures usually can’t be patched into perfection or even into acceptability. I’ve got two related lessons here. First, you can and should use your spreadsheets and dynamic simulations to identify and fix performance, load and reliability problems during the design phase.
Second, don’t wait until the very end, but integrate performance, load and reliability testing throughout unit, subsystem, integration and system test. If you wait until the end and try throwing more hardware at your problems, it might not work. The later in the project you are, the fewer options you have to solve problems. This is doubly true for performance- and reliability-released design and implementation decisions.
During the interactive voice-response server project, one senior technical staff member built a spreadsheet model that predicted many of the performance and reliability problems we found in later system testing.
Sadly, there was no follow-up on his analysis during design, implementation or subsystem testing. By the time we got involved, during integration and system testing, the late discovery of problems led project management to try patching the interactive voice-response server, either by tweaking the telephony subsystem or adding hardware.
Patching of one problem would resolve that particular problem and improve performance, only to uncover another bottleneck. This became a slow, painful, onion-peeling process that ultimately didn’t resolve the problems (see Figure 5 below).
FIGURE 5: PATCHING’S NOT THE ’BEE’S KNEES’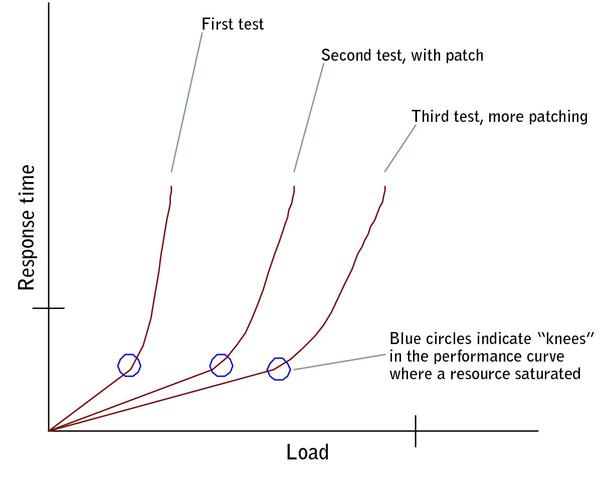
In a case where we did apply performance modeling and testing consistently and throughout the life cycle, in the Internet project, we started with a spreadsheet during initial server system design. That initial design was turned into a simulation, which was fine-tuned as detailed design work continued. Throughout development, performance testing of units and subsystems was compared with the simulation. This resulted in relatively few surprises during testing.
We quickly learned that we’re not likely to get models and simulations right from the very start; we had to iteratively improve them as we went along. Your tests will probably also have problems at first, so plan to modify them to resolve discrepancies between the predicted and observed results.
Time to Get Started
We’ve covered a lot of ground. Perhaps some of the challenges described here have also been part of your experience. You can start to implement some of these lessons by assessing your current practices in performance, load, and reliability testing. How well or poorly does your company do in applying each of these five lessons? Which common mistakes are you making? What warnings are you not heeding? Which tips for success could you apply?
Based on this assessment, see if you can put together a short action plan that identifies the organizational pain and losses associated with the current approach. Then develop a path toward improvement. The goal is to avoid expensive, unforeseen field failures by assessing and improving your performance, load, and reliability risk-mitigation strategy throughout the life cycle.
Once you have your plan in place, take it to management. Most of the time, managers will be receptive to a carefully thought-out plan for process improvement based on a clearly articulated business problem and a realistic solution. As you implement your improvements, don’t forget to continually reassess how you’re doing. I hope that my mistakes and those I’ve observed in others can help make your projects a success.
About the Author
 Rex Black – President and Principal Consultant of RBCS, Inc
Rex Black – President and Principal Consultant of RBCS, Inc
With a quarter-century of software and systems engineering experience, Rex specializes in working with clients to ensure complete satisfaction and positive ROI. He is a prolific author, and his popular book, Managing the Testing Process, has sold over 25,000 copies around the world, including Japanese, Chinese, and Indian releases. Rex has also written three other books on testing – Critical Testing Processes, Foundations of Software Testing, and Pragmatic Software Testing – which have also sold thousands of copies, including Hebrew, Indian, Japanese and Russian editions. In addition, he has written numerous articles and papers and has presented at hundreds of conferences and workshops around the world. Rex is the immediate past president of the International Software Testing Qualifications Board and the American Software Testing Qualifications Board.